이 글은 NAACL 2021에 게재된 논문 Personalized Response Generation via Generative Split Memory Network에 대한 요약이다.
Motivations
생성 및 대화 시스템 진보에도 불구하고, 특정 개인 특성을 text generation 시스템에 적용하여 개인화된 응답 (personalized response)을 전달하는 것은 상대적으로 덜 연구되어있다.
Chit-chat agents는 human-like conversational systems을 통해 사람들과 상호작용하고 인간 대화의 의미를 이해한다. 이를 통해, user experience를 향상시키는 더 나은 응답을 만든다. Data-driven 접근 방식을 통해 많은 성공을 거뒀지만. consistent personality의 결여에 대한 이슈가 남아있다.
Why?) 대담자들의 personality를 무시하면서 그들의 대화에 대해 훈련하기 때문이다.
같은 질문에도 사람들마다 다른 personality와 background 때문에 다른 응답을 말한다. 따라서 Personalization을 modeling과 응답 생성의 evaluation에 통합하여 chit-chat agents을 완성해야 한다.
Personalized conversations에 대한 모델의 성능을 평가하기 위해 여러 personality-related dialogue datasets이 존재한다.
PERSONA-CHAT, Facebook's Reddit dataset
PERSONA-CHAT은 persona를 문장으로써 사전정의한 상태에서 annotators에 의해 수집된다. 이 경우는 real personality를 녹여냈다고 할 수 없다. 인공적으로 생성된 대화는 응답자와 personalities를 적절히 표현할 수 없고 이는 dataset bias 문제로 이어진다. 예를 들어보자. 내성적인 성격의 annotator는 사교적인 personas를 가진 사람의 응답을 모방하기 어렵다. 또한, 이 corpus에 의해 커버되는 personas 수는 제한적이다.
Facebook's Reddit은 휴리스틱하게 comment history로부터 선택된 문장 집합이다. 문장 검색을 위한 heuristic 규칙의 한계 때문에 user의 일반적인 특징이 잘 표현되지 못 할 수 있다.
그래서 이 논문은 1.5M개의 대화와 300k명의 users로 구성된 open-domain response generation dataset 인 personalized Reddit dataset PER-CHAT을 공개한다.
Dataset
Reddit에서 사용자의 self-reported messages를 기반으로 추론된 favorites, gender, residence, self-description과 같은 이산적인 사용자 속성을 포함하면서, 사용자들에 대한 세부적으로 얻어진 개인 정보를 커버한다. 다만, single-turn dialog dataset이다. 데이터셋 취득에 대한 세부적인 내용은 논문을 참고바란다.
Generative split memory network
PER-CHAT을 기반으로, 다양한 개인 정보를 통합하는 generative split memory network를 살펴보자. 해당 네트워크는 user profile과 user comment history에 대한 split memories를 가진다. 다만, 메인 모델은 seq2seq with attention으로 설계되었다.
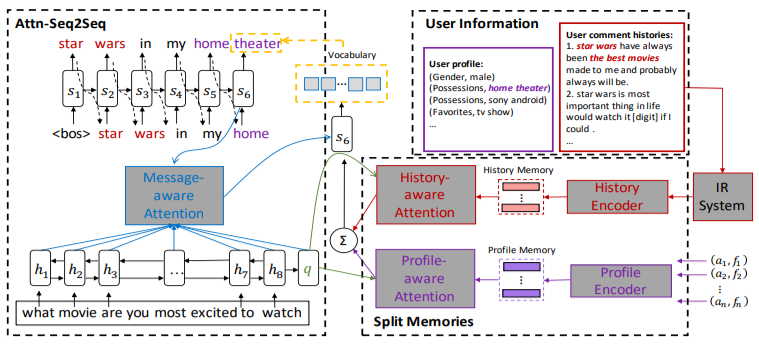
Conversation 를 Question, Response, User의 tuple인 라 하자. User 은 다음 세 가지 sources의 정보로 구성된다.
: username, : profile attributes, : user's comments (A set of comment histories the user made)
여기서 는 key-value pair 이다.
주어진 conversation 에 대해, query-related comment set 을 얻기 위해 검색 시스템 (retrieval system)에 input comments 을 feeding 한다. 그리고 memory network encoder는 관련된 comment history의 representations을 계산한다. 동일하게, profile 속성들은 또 다른 encoder에 의해 separate profile memory로 추가된다. 각 time step에서 decoder는 마지막 응답을 생성하기 위해 comment histories의 집약된 representations과 profile attributes를 활용한다.
Evaluation
Perplexity, BLEU, BERTScore에 대해 baselines과 비교하며, 추가적으로 user comments와 생성된 문장들 간 persona consistency를 평가하기 위해 Dialog NLI dataset에 훈련된 sequence 분류 모델을 사용하여 C score를 계산한다. 또한, Profile Consistency score (PC-Score) metric을 통해 주어진 user profiles을 가지고 persona consistent responses를 생성하는지를 측정한다.




댓글