이 글은 논문 SOLOIST: Building Task Bots at Scale with Transfer Learning and Machine Teaching 이해를 위한 글이다.
Abstract
SOLOIST는 대규모 task bots을 build하기 위해 transfer learning과 machine teaching을 사용한다. 또한, 고전적인 modular TDS를 단일 neural model인 Transformer-based auto-regressive language model로 파라미터화한다. 여러 유형의 dialog corpora에 pre-trained 모델은 machine teaching을 거친 약간의 task-specific dialogs만으로 새로운 tasks를 성취하도록 효율적으로 적응될 수 있다. 여기서 해당 dialogs는 human teachers과 시스템과의 상호작용에 의해 생성된 training samples이다.
Contributions
1) SOLOIST는 CamRest676과 Multi-WOZ를 포함하여 잘 연구된 task-oriented dialogue benchmarks에서 SoTA를 달성한다.
2) Few-shot fine-tuning settings에서, SOLOIST는 기존 방법들을 상당한 격차로 outperform한다.
3) Machine teaching의 사용은 일반적으로 fine-tuning을 위한 labeling cost를 줄인다.
Methods
Task bot building은 two stages로 진행된다.
1) Pre-training stage : GPT-2를 사용하여 모델을 초기화하고, 다형의 large dialog corpora를 사용하여 Transformer-based, task-grounded, response generation model을 훈련시킨다.
2) Fine-tuning stage : Machine teaching을 거친 소수의 task-specific dialogs를 사용하여 특정 (신규) task를 완수하도록 pre-trained SOLOIST 모델을 적응시킨다.
SOLOIST는 pre-trained model에서 new task bot으로 아래 두 가지 능력을 성공적으로 전이함으로써 대규모 task bots을 build하는 효과적인 방법이라는 것을 여러 실험을 통해 보여준다.
1) The capability of NLU and NLG learned on raw text
2) The capability of grounding system responses in user goals and real world knowledge for task completion, learned on the out-domain dialog corpora
SOLOIST
GPT-2는 엄청난 양의 Open Web text data에서 훈련된 auto-regressive LM이다. 그러나 GPT-2가 현실성 있는 일관된 대답을 하기 위해선 대화 데이터에 fine-tuning 되어야 한다 (DialoGPT). 대화 데이터에 학습된 GPT-2는 human-like 응답을 생성할 수 있지만 grounding의 결여로 인해 어떠한 task를 수행하기엔 적절치 않다. 그에 반해, SOLOIST는 task completion을 위해 user goals과 real-world knowledge에 기반된 응답을 생성하도록 pre-training 된다.
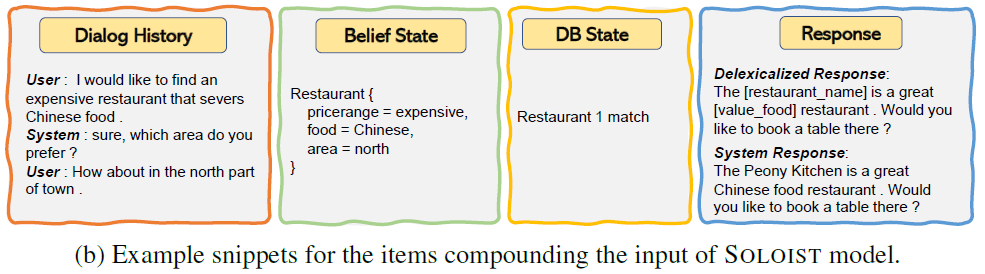
SOLOIST는 task completion을 위한 stateful decision-making model이다. 따라서 grounding information으로 annotation된 task-oriented dialog sessions을 사용하여 pre-training 한다. 특히, 훈련 데이터 내 각 dialog 턴은 다음과 같이 표현된다.
여기서 는 현재 dialog turn까지의 dialog history, 는 human annotation으로부터 취득된 dialog belief state, 는 를 사용하여 DB로부터 자동적으로 검색된 DB state, 은 자동적인 post-processing을 사용하여 생성될 수 있는 자연어로 된 delexicalized dialog response다. 내 각 항목은 그 자체로 sequence의 token이다. 위 이미지는 해당 tokens의 예시를 보여준다. 따라서 모델 훈련 시 긴 sequence로써 해당 항목들을 결합하여 다룬다. 아래 그림에 그 예시가 나타나있다. SimpleTOD와 약간만 다르고 거의 유사한 형태로 보여진다.

SOLOIST 모델은 Belief states와 DB states의 labels을 가진 공개적으로 이용가능한 다형의 dialog corpora를 사용하여 pre-training 된다. Pre-trained 모델은 task-specific user goals와 DB에 기반된 responses를 생성하기 위해 새로운 task에 fine-tuning 될 수 있다.
Task-Grounded Pre-Training
훈련 데이터로 개의 samples 이 주어지면, sequence generation probability 을 모델링하는 neural model을 build하는 것이 목표이다. 이 목표를 달성하도록 학습을 위해 multi-taks objective를 사용한다. 여기서 각 task는 self-supervised learning task다.
TDS의 sequential 구조를 이용하기 위해 joint probability 는 다음과 같이 auto-regressive manner로 인수분해될 수 있다:
DB state 는 belief state 가 주어지면 deterministic DB-lookup process (e.g., via an API call)를 사용해 얻어지기 때문에 위 인수분해는 이라는 사실이 기반된다. 위 수식에서 는 grounded response generation, 는 belief prediction이다. 이렇게 joint distribution 문제는 두 개의 sub-problems으로 분해될 수 있고 , 은 sequences이므로 각각 left-to-right auto-regressive manner로 다음과 같이 귀결될 수 있다.
Task 1: Belief Prediction
길이가 인 belief state sequence에 대해 다음과 같이 belief state 예측을 위한 objective가 정의된다.
여기서 는 전 모든 tokens을 가리킨다.
Task 2: Grounded Response Generation
길이가 인 delexicalized response 는 를 기반으로 왼쪽에서 오른쪽으로 token-by-token으로 생성된다. Training objective는 다음과 같이 정의된다.
Task 3: Contrastive Objective
Contrastive objective는 matched items (positive samples )를 촉진시키고 mismatched items (negative samples )을 억제하기 위해 사용된다. Negative samples는 50% 확률로 내 약간의 items을 dataset 로부터 랜덤하게 샘플링된 다른 items으로 대체하여 생성된다. 위에 architecture 그림에서 보듯, special token [EOS]를 위해 sequence 내 모든 tokens이 참여하기 때문에, [EOS]에 대한 output feature는 모든 items의 융합된 representation이다. 따라서 sequence 내 tokens이 matched ()인지 mismatched ()인지를 예측하기 위해 해당 feature의 top에 binary classifier를 적용한다. Objective는 다음과 같이 cross-entropy를 가지고 정의된다.
Negative samples 은 의 확률에 따라 각기 다른 유형으로 생성된다.
1) Negative : belief state item만 대체
2) Negative : response item만 대체
3) Negative : belief state와 response items을 대체
최종적으로, 모델은 다음 objective를 최대화하는 것을 거쳐 학습된다.
Fine-Tuning and Machine Teaching
새로운 task로 SOLOIST를 배포할 때, pre-training에서 사용된 형식과 동일하게 task-specific 를 수집한다. 그 다음, pre-training에서 사용된 동일한 objective로 활용하여 fine-tuning 한다.
Machine teaching은 "teacher"로써 도메인 전문가들의 지식과 전문성을 이용하는데 집중하는 active learning paradigm이다. 이 paradigm이 강조하고 싶은 점은 데이터 과학자와 기계학습 전문가가 아니더라도 teacher가 되는 것이 가능하다는 것이다. Dialog authors가 특정 task에 pre-trained SOLOIST 모델을 배포한 뒤, teacher와의 대화를 통해 잘못된 응답들이 개정된다. 개정된 대화들은 다시 학습 데이터로 이용되어 fine-tuning 된다.
Experiments
Implementation Details
Training data 내 각 dialog turn은 로 구성된 sequence를 형성하도록 처리된다. 예를 들어, 위 (b) 그림의 대화는 다음과 같이 표현된다.

해당 sequence는 BPE를 사용하여 토큰화된다. SOLOIST의 task-grounded pre-training은 117M-parameter인 GPT-2로 초기화되고 Adam을 사용한다. Pre-training과 fine-tuning에 사용된 dialog corpora는 다음과 같다. Pre-training 데이터와 fine-tuning 데이터가 overlap되지 않는 것을 확실히 하기 위해 서로 유사한 데이터는 제외된다.

Training examples는 최대 길이 512로 잘려진다. Decoding 방식으로 Nucleus sampling이 사용되었다. 여기서 sampling top-p는 0.2~0.5로 설정된다. 최상의 hyper-parameters는 validation set에 대한 grid-search를 통해 선택된다. Machine teaching 실험을 위해 pre-trained 모델은 SGD로 fine-tuning 된다.
Dialog Dataset for Fine-tuning
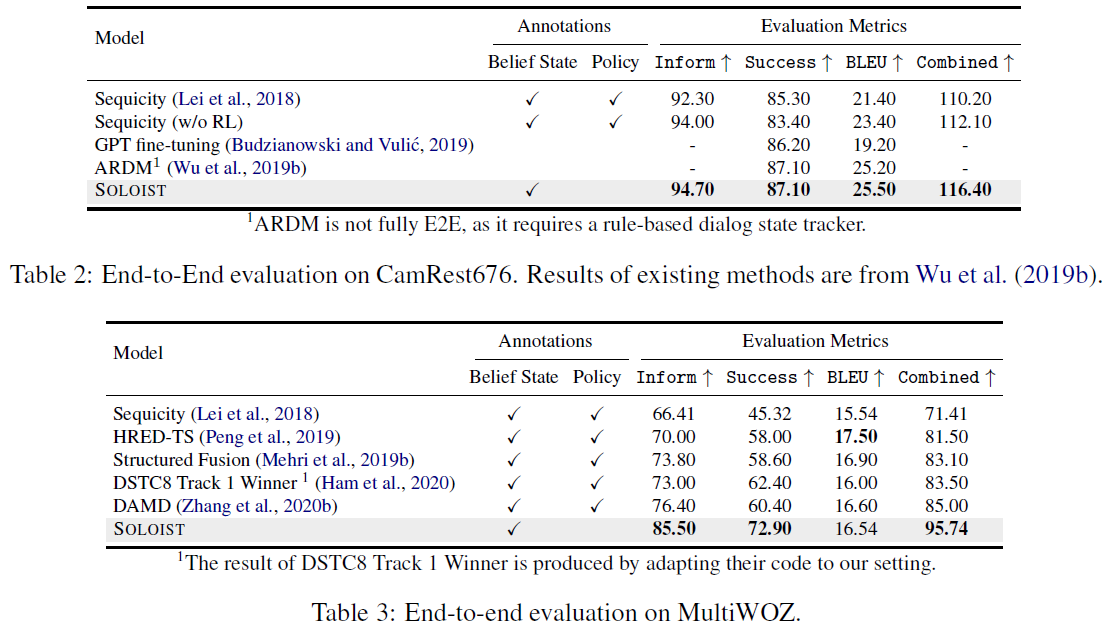
두 개의 well-studied 데이터셋에 대해 SOLOIST의 end-to-end dialog system 성능을 검증한다.
1) CamRest676
단일 도메인 TOD corpus로, training/validation/testing 대화 수는 408/136/136 이다. Sequicity 따라, 식당 이름, 전화번호, postcode와 같은 slot의 slot names을 가진 온톨로지 내 발생한 각 token을 delexicalization한다.
2) MultiWOZ
Multi-domain TOD dataset으로, training/validation/testing 대화 수는 8438/1000/1000 이다. 각 dialog session은 1~3개의 domains을 포함한다.
Automatic evaluation metrics으로 BLEU, Inform (시스템이 적절한 entity를 제공했는가), Success (모든 요구된 속성에 대답했는가), Combined score를 계산한다.
Baselines
DAMD는 modular system이지만 각 dialog module은 neural network를 사용하여 구현되었고, 전체 시스템은 end-to-end manner로 훈련된다. Sequicity는 multi-action data augmentation을 사용하지 않다는 것을 제외하고 DAMD와 비슷하다. ARDM은 dialog context가 주어지면 role-aware responses를 생성하기 위해 pre-trained model로 GPT-2를 활용한다. 하지만 task completion을 위해 분리된 dialog state tracker를 가지고 작업해야만 한다. HDSA는 BERT 기반 dialog policy와 graph structure dialog act representations를 사용하여 응답을 생성하는 modular dialog system이다.
Few-Shot Evaluation
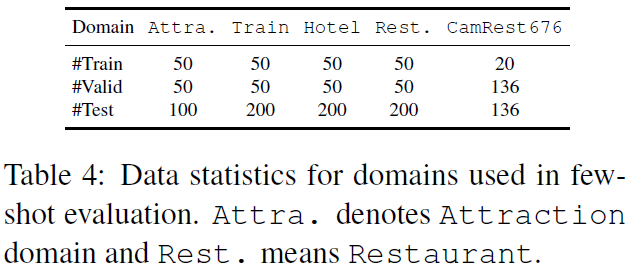
Few-shot fine-tuning setting은 dialog systems을 평가하는데 더 현실적인 설정이다. Few-shot fine-tuning을 위해 CamRest676과 MultiWOZ 데이터셋을 재구성한다. MultiWOZ 데이터셋의 경우 하나의 도메인만을 포함하는 dialog tasks를 샘플링한다. Attraction, Train, Hotel, Restaurant 도메인이 사용되며, Police, Taxi, Hospital 도메인은 task completion을 위한 dialog state tracking을 명확히 요구하지 않기 때문에 사용되지 않는다. 각 도메인에 대해 위 표에 표시된대로 랜덤하게 샘플링된다.

SOLOIST와 SimpleTOD가 모델 학습과 architecture에서 다른 점은 input을 넣어주는 special tags와 multi-task loss 정도로, 굉장히 유사한 접근법이라고 볼 수 있다. 물론 SOLOIST는 few-shot에 집중하여 SimpleTOD와 직접적인 비교는 어려울 수 있겠다. 그러나 SimpleTOD와 Dialog state tracking의 정확도는 비교했음에도 Combined score를 비교하지 않은 것은 의문이 든다. SOLOIST는 DST 평가에서 SimpleTOD보다 높은 이유를 task-grounded pre-training으로 이야기한다.




댓글