End-to-End TDS (Task-oriented Dialogue Systems)을 위한 작업 중 하나인 GraphDialog: Integrating Graph Knowledge into End-to-End Task-Oriented Dialogue Systems (EMNLP 2020) 논문의 이해를 돕기 위한 글이다.
Motivations
End-to-End TDS는 plain text inputs으로부터 바로 시스템 응답을 생성하는 것을 목적으로 한다. 이 시스템 위해 다음 2가지의 challenges가 남아있다.
1) How to effectively incorporate external knowledge bases (KBs) into the learning framework
2) How to accurately capture the semantics of dialogue history
이 논문은 위와 같은 KB와 Dialogue history를 어떻게 효율적으로 이용할 것인가에 대한 고민을 Graph 구조를 적극 이용함으로써 해결하고자 한다.
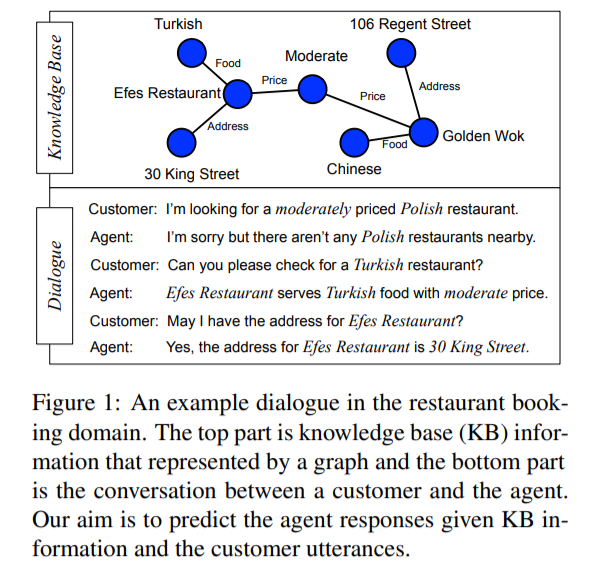
위 대화는 레스토랑 예약을 위한 대화 예시다. 설명의 편의를 위해 대화 내용을 아래에 한국말로 옮겨놓았다.
User: 적당한 가격의 폴란드 식당을 찾고 있어요.System: 죄송해요, 근처에 폴란드 식당이 없네요.User: 터키 식당은요?System: Efes 식당이 적당한 가격에 터키 음식을 팔고 있네요.User: Efes 식당 주소 좀 알려줄 수 있나요?System: 네, Efes 식당 주소는 30 King Street 입니다.
이 대화에서 system의 필요한 능력을 확인해보자. 일단, system의 목적은 자연어 형식으로 user를 만족시키도록 정확한 식당 entities를 제공하는 것이다. 그러기 위해선 KB (Knowledge Base)에 query를 잘 날려 적절한 정보를 얻을 수 있어야 한다. 또한, 앞의 대화 기록을 이해하여 "터키 식당은요?" 라는 말로부터 "적당한 가격의 터키 식당" 을 묻는다는 것을 알 수 있어야 한다.
해당 논문은 KB와 dialogue의 dependency parsing tree에 대한 graph structural information을 이용함으로써 이러한 문제들을 해결하고자 한다.
이전의 노력들
TDS 구조 설계에 대한 주요 흐름은 pipeline 방식과 end-to-end 방식으로 거칠게 나눌 수 있다. Pipeline 접근은 신규 도메인의 adaption과 credit assignment에 대한 어려움이 존재한다. Pipeline은 보통 NLU, DST, Dialog Policy, NLG 모듈로 모델을 구성하여 문제를 해결한다. 이러한 접근은 복잡한 모델 설계로 이어지고, 각 모듈의 성능이 전체 시스템 향상에 반드시 기여하지 않을 수 있다 [Z. Zhang et al., 2020]. Dialogue history를 output response로 바로 맵핑하는 End-to-end methods는 이러한 pipeline 접근의 결함을 완화시킨다. 그러나 보통 KB 데이터를 다룰 적절한 프레임워크의 결여로 인해 KB의 비효율적인 사용으로 고통받는다.
이러한 이슈를 해결하기 위해, 이전의 end-to-end dialogue 연구들은 memory networks를 채택했다. 그러나 해당 연구들은 memory를 list 구조로 볼 수 있기에 KB의 기본 구조가 선형이라고 가정했다. 그러한 가정은 entities 간의 관계 포착을 어렵게 한다.
GraphDialog
KB는 entities가 nodes고 relations이 edges인 graph 구조로 볼 수 있다. 또한 다른 tasks에서 dependency relationships와 같은 구조적 지식은 모델의 일반화 능력에 효율적임을 보여주었다. 그러한 관점을 통해 graph-based end-to-end task-oriented dialogue model (GraphDialog)을 제안했다.
Overall architecture
GraphDialog는 Encoder, Decoder, Knowledge graph로 구성된다. 전체 architecture는 다음과 같다.

여기서 는 dialogue history 내 어떤 단어에 대응하는 token이다. Encoder는 을 입력으로 하여 를 고정된 길이의 벡터로 인코딩한다. 그런 뒤, 해당 벡터는 hidden state initialization을 위해 decoder의 입력으로 주어진다. 위 그림에는 안 그렸지만 외부 knowledge data를 저장하고 검색하기 위해 knowledge graph 를 이용한다. Decoder는 knowledge graph에 query하는 것을 거쳐 로부터 entities를 복사하거나 vocab으로부터 tokens을 생성하여 시스템 응답 을 생성한다.
Graph Encoder

위 그림은 Graph Encoder 구조로, 위는 forward graph, 아래는 backward graph다. Input부터 encoder 구조까지 자세히 살펴보자.
Dialogue Graph
먼저, Adjacency와 dependency 관계 같은 단어의 의미적으로 풍부한 표현들을 학습하도록 하기 위해, off-the-shelf tool spacy를 사용하여 dialogue history 내 단어들 간 dependency 관계를 추출한다.
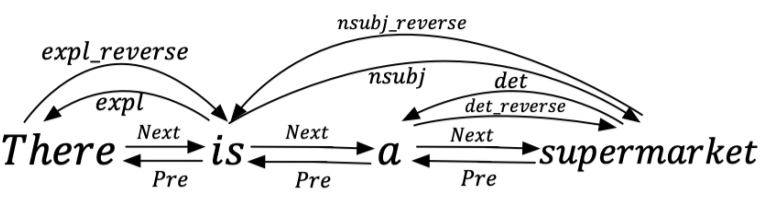
위 그림은 dependency parsing 결과 예시다. 단어들 간 양방향 edges는 dependents에서 heads로, heads에서 dependents로 정보가 흐르도록 한다. Spacy를 이용해 dependency parsing을 하는 방법은 여기 잘 나와있어 참고하면 좋을 듯하다.
그 다음, 위 그림처럼 단어들 간 sequential 관계 (i.e., Next and Pre)를 앞에서 취득된 dependency relations와 결합하여 dialogue graph를 구성한다. Bidirectional representation을 학습하기 위해 dialogue graph는 forward graph와 backward graph로 나뉜다.
Recurrent Cell Architecture

위는 Recurrent unit을 그림으로 나타낸 것이다. 그림만 봐선 너무 난잡하고 복잡해서 쉽사리 구조를 알기 어렵다. 그림보다 수식으로 보는 것이 훨씬 쉽다. 개인적인 생각이지만 이런 figure는 지양해야 하지 않을까...
Cell의 입력은 input word vector 와 predecessor hidden states 로 구성된다. 아래는 cell의 연산을 나타낸 것이다.
1) Reset gate
내 개의 hidden states에 대해 각각 위 수식을 통해 번째 hidden state에 대한 reset gate 계산, 여기서 와 은 학습 파라미터다.
2) Candidate hidden state
계산된 reset gate 를 가지고 현재 input 의 contextualized representation 를 계산한다. 는 다.
3) Input and hidden states 에 선형변환 적용 => ,
4) 에 candidate hidden state 추가 =>
5) Hidden states 를 keys, 현재 input states 를 query로 사용하여 masked attention mechanism 수행
논문에서는 로 표기됐는데 문맥 상 같다. 그게 아니라면 은 계산해놓고 쓰이는데가 없다. Masked attention mechanism은 학습 과정에서 pad 정보가 영향을 미치는 것을 피하기 위해 pad token에 대응하는 hidden state에 로 설정한다. 이렇게 하면 time step마다 predecessors의 수가 달라도 입력을 다루며 attention mechanism을 적용할 수 있다.
여기서 는 학습 파라미터이고, 은 의 번째 벡터다. 은 mask operation이다.
6) Time step 에서 cell output hidden state 계산
위에서 말했듯 forward graph와 backward graph를 통해 양방향적으로 dialogue history를 계산하는데 이때 각 graph에서 얻은 representations을 concat한다. 따라서 dialogue history의 최종 representation은 다음과 같다.
Multi-hop Reasoning Mechanism over Knowledge Graph
KB의 graph 정보를 탐색하는 직접적인 방법은 graph 구조로써 KB를 표현하고 decoder hidden states를 가지고 attention mechanism을 사용해서 graph를 query하는 것이다. 그러나 저자의 실험에서는 이 접근이 좋은 성능을 보여주지 못 했다고 한다. 그리고 이러한 결과의 이유는 해당 방법의 poor reasoning ability 때문이라고 짐작했다. 이러한 이슈를 해결하기 위해, reasoning ability의 강화와 self-attention을 거쳐 entities 간 graph structural 정보를 캡쳐하는 multi-hop reasoning mechanism을 가지고 graph를 확장한다. 이 모듈을 knowledge graph module로 정의한다.
Knowledge graph module은 다음 두 가지의 훈련 파라미터 집합으로 구성된다.
여기서 는 tokens을 vector representations으로 맵핑시키는 embedding matrix, 는 self-attention coefficients를 계산하는 weight vector다. 는 최대 hop의 개수다. 아래는 knowledge graph의 output vector를 계산하는 과정을 나타낸다.
모델은 input graph에서 hop을 반복하고 각 hop 에서 reading head로써 query vector 를 채택한다.
1) Embedding layer 를 사용하여 Graph 내 각 노드 의 연속 벡터 representations를 계산 후 self-attention 수행하기 위해 attention coefficients 계산
여기서 는 LeakyReLU 활성화 함수다. 와 는 hop 에서 graph 내 번째 노드와 번째 노드에 대한 노드 벡터다. 는 concatenation 연산이다.
2) 어떤 노드의 모든 첫 번째 이웃에 대한 각 노드 의 coefficients를 normalization (Softmax)
여기서 는 노드 를 포함한 노드 의 첫 번째 이웃 노드다.
3) 내 이웃 노드들의 weighted sum에 의해 각 노드 의 representation을 업데이트
4) Graph에서 업데이트된 노드에 attention을 부여하기 위해 hop 에서 각 노드 에 대한 attention weight 계산
이제 knowledge graph의 output을 얻기 위해, 위와 같은 self-attention mechanism(1,2)과 node representation 에 대한 업데이트 전략(3)을 적용한다. 여기서 는 adjacent weighted tying strategy 채택으로 인해 사용된다. Output을 위한 update node representation은 로 표기된다.
5) Weighted sum을 통해 graph 계산
6) 를 통해 다음 hop에 대한 query vector 를 업데이트
Knowledge graph의 최종적인 output은 이고 dialogue history 와 함께 decoder에 입력된다.
Decoder
Decoder의 구조는 아주 간단하다. Encoder에서 계산된 dialogue history와 graph output을 이용해서 현재 time-step의 word를 생성한다.
여기서 은 이전에 생성된 단어, 은 이전 hidden state다. 그리고 entites는 sketch response를 학습하기 위해 특정 tags로 대체되어 학습된다.
는 위처럼 을 생성하는데 사용되고 추가적으로 graph 내 모든 노드에 대한 graph distribution 를 생성하기 위해 knowledge graph를 query하는데 사용된다. 는 knowledge graph 의 last hop의 attention weights를 사용하여 계산한다.
각 timestep 에서, 으로부터 생성된 단어가 tag면, decoder는 에 따라 가장 큰 attention value를 가진 graph entities를 복사하기 위해 선택한다. 그렇지 않으면, decoder는 으로부터 target word를 생성하도록 학습된다.
훈련 동안 (, ), ()를 쌍으로 계산하는 두 개의 cross entropy loss를 최소화한다. 여기서 은 현재 output 에 대응하는 node id다.
실험
데이터셋은 차 네비게이션 task에 대한 데이터셋인 SMD와 MultiWOZ 2.1 데이터셋을 사용했다. 주요 metric은 BLEU와 Entity F1을 사용했고 KG의 최대 홉 개수인 가 3일 때 제일 좋은 성능을 보였으며 비교하는 baselines을 모두 outperform했다.
SMD에서는 BLEU 13.66, Entity F1 57.42, MutliWOZ 2.1에서는 BLEU 6.17, Entity F1 11.28을 달성했다. 참고로, ACL 2021에 나온 CDNet은 SMD에서 BLEU 17.8, Entity F1 62.9, MultiWOZ 2.1에서 BLEU 11.9, Entity F1 38.7을 달성했다.




댓글