Object detection 분야에서 쓰이는 모델로는, Faster-RCNN, MobileNet, SSD 등 많은 모델이 있지만 그 중 YOLO 모델에 대해 자세히 알아보려 한다.
일단, 현 시점에서는 YOLO, YOLOv2, YOLOv3(YOLO 9000)까지 모델이 개발되었고 각 모델마다 변화에 따른 장단점이 생겨났다. 필자는 YOLOv3를 사용해서 프로젝트들을 진행해본 결과 나름 괜찮은 성능의 결과를 얻을 수 있었다. 그러나 YOLOv2에 비해 느리다는 것이 단점이었다. 구조적 관점에서 이러한 차이들을 파악하기 전 기본적인 바탕이 되는 YOLO 모델의 원리에 대해 알아보는 것이 이번 글의 목표다.
YOLO
가장 기본이 되는 YOLO 모델의 원리를 설명하고자 한다.
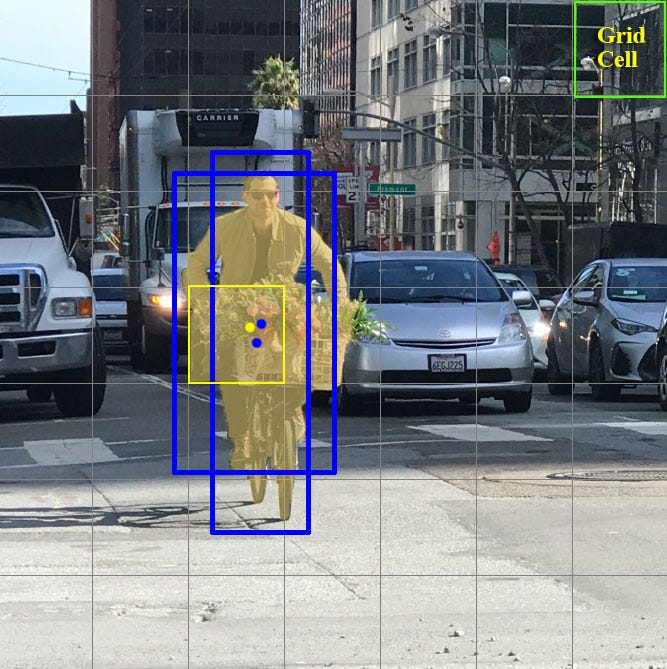
먼저 간단히 설명하자면, 예측하고자 하는 이미지를 SxS Grid cells로 나누고 각 cell마다 하나의 객체를 예측한다. 그리고 미리 설정된 개수의 boundary boxes를 통해 객체의 위치와 크기를 파악한다. 이때, 각 cell마다 하나의 객체만을 예측할 수 있기 때문에 여러 객체가 겹쳐있으면 몇몇의 객체는 탐지를 못 하게 될 수 있다.
그럼 이제 각 cell에서 어떻게 객체를 예측하는지 살펴보자.
각 cell은 다음 조건 하에 예측을 진행한다.
- B개의 boundary boxes를 예측하고 각 box는 하나의 box confidence score를 가지고 있다.
- 예측된 box 수에 관계없이 단 하나의 객체만 탐지한다.
- C개의 conditional class probabilities를 예측한다.

각 요소를 자세히 살펴보자. 각 boundary box는 객체의 위치 (x, y), 객체의 크기 (w, h), box confidence score로 구성되어 총 5개의 인자를 가지고 있다. 여기서 box confidence score는 box가 객체를 포함하고 있을 가능성(objectness)과 boundary box가 얼마나 정확한지를 반영한다. Conditional class probabilities는 탐지된 객체가 어느 특정 클래스에 속하는지에 대한 확률이다.

각 score는 수학적으로 위와 같이 정의된다. Class confidence score는 분류와 지역화(localization) 둘 다에 대한 confidence를 측정한다.
Network design

예를 들어, PASCAL VOC를 평가하기 위해 7x7 grids, 2 boundary boxes, 20 classes를 사용했다고 하자. 그러면 1 cell = 2 x (x, y, w, h, confidence) + 20 = 30 이므로 출력 결과의 형태는 (7, 7, 30)이 된다.
이제 YOLO의 주요 개념은 (7, 7, 30) 텐서를 예측하는 CNN 네트워크를 구축하는 것이다. CNN 모델은 spatial dimension을 1024개의 channel을 가진 7x7 dimension으로 줄인다. YOLO는 7x7x2 boundary box 예측을 만들기 위해 2개의 fully-connected layers를 통해 linear regression을 수행한다. 결론적으로, YOLO는 24개의 convolutional layers와 2개의 fully-connected layers로 구성되어 있다. 몇몇 convolution layers는 1x1 커널을 사용해서 feature maps의 깊이를 줄이고 최종적으로 (7, 7, 30) 형태의 텐서를 만들어낸다.
Loss function
YOLO는 각 grid cell마다 다수의 bounding boxes를 예측하지만 true positive에 대한 loss를 계산하기 위해 탐지된 객체를 가장 잘 포함하는 box 하나를 선택해야 한다. 이를 위해 ground truth와 IOU를 계산하여 가장 높은 IOU를 가진 하나를 선택한다. 이로써 크기나 가로, 세로 비율에 대해 더 좋은 예측 결과를 얻을 수 있다.
YOLO는 loss를 계산하기 위해 예측과 ground truth 사이의 sum-squared error를 사용하며, loss function은 다음 세 가지로 구성된다.
- classification loss
- localization loss (errors between the predicted boundary box and the ground truth)
- confidence loss (the objectness of the box)
Classification loss
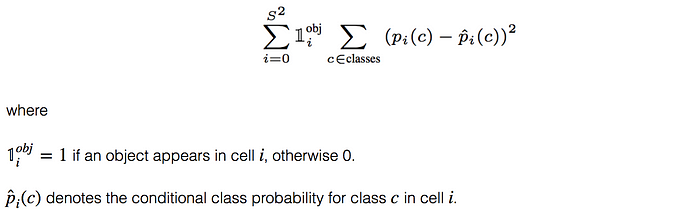
객체가 탐지되었다면, 각 cell의 classification loss는 각 클래스의 class conditional probabilities의 squared error다. 위에 수식에서 볼 수 있듯이 객체가 탐지되지 않았다면 0이 된다.
Localization loss
localization loss는 예측된 boundary box의 위치와 크기에 대한 에러를 측정한다.

마찬가지로, 객체가 탐지되지 않은 경우에 대해서는 loss 값을 계산하지 않는다. 수식을 살펴보면, 위치는 sum squared error를 그대로 적용하지만 크기에 대해서는 각 높이와 너비에 대해 루트 값을 씌워 계산했다. 이렇게 하는 이유는 절대 수치로 계산을 하게 되면 큰 box의 오차가 작은 box의 오차보다 훨씬 큰 가중치를 받게 된다. 예를 들어, 큰 box에서 4 픽셀 에러는 너비가 2 픽셀인 작은 box의 경우와 동일하게 된다. 따라서 YOLO는 bounding box 높이와 너비의 제곱근을 예측하게 된다. 추가적으로, 더 높은 정확도를 위해 λcoord (default: 5)를 loss에 곱해 가중치를 더 준다.
Confidence loss
객체가 탐지된 경우의 confidence loss function은 아래와 같으며,

객체가 탐지되지 않은 경우는 loss function은 아래와 같다.

둘의 다른 점은 객체가 탐지되지 않은 경우는 λnoobj (default: 0.5)에 의해 loss의 가중을 적게 한다는 점이다. 이렇게 하는 이유는 클래스 불균형 문제를 방지하기 위함이다. 사실 대부분의 box가 객체를 포함하고 있지 않은 경우가 더 많기 때문에 배경에 대한 가중을 줄이지 않는 경우 배경을 탐지하는 모델로 훈련될 수 있다.
Final Loss
최종 loss는 위의 모든 loss를 더한 것이다.
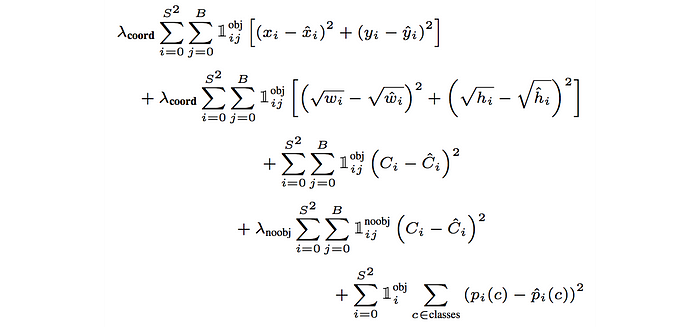
Non-maximal suppression
같은 객체에 대해 여러 개의 탐지(예측된 boundary boxes)가 있을 수 있다. 이것을 고치기 위해, YOLO는 더 낮은 confidence를 가진 중복된 것을 제거하는 non-maximal suppression을 적용한다.
구현 방법은 다음과 같다.
- confidence score 순으로 예측을 정렬한다.
- 제일 높은 score에서 시작해서, 이전의 예측 중 현재 예측과 클래스가 같고 IOU > 0.5인 것이 있었으면 현재의 예측은 무시한다.
- 모든 예측을 확인할 때까지 Step 2를 반복한다.
다음은 YOLOv2, YOLOv3의 변경점에 대해 살펴본다.
참고 : https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
'A·I' 카테고리의 다른 글
| [object detection] YOLO에서 YOLOv2로의 변경점 (0) | 2019.11.12 |
|---|---|
| [object detection] Single Shot Multibox Detector (SSD) 아키텍쳐 분석 (0) | 2019.08.08 |
| 주차 구역 인식(Vision-Based Parking-Slot Detection) 논문 리뷰 (12) | 2019.07.04 |
| Keras로 구현하는 DCGAN (4) | 2019.05.26 |
| What is AI and an Agent? (0) | 2019.04.18 |



댓글