Single Shot MultiBox Detector[논문]는 object detection을 위한 아키텍쳐다. object detection을 위한 여러 아키텍쳐가 있는데 R-CNN, Fast R-CNN, Faster R-CNN 등 2-stage detector가 아닌 YOLO와 같은 1-stage detector에 속한다.
2016년 11월에 발표된 모델이고 PascalVOC, COCO 데이터셋 등과 같은 표준 데이터셋에서 FPS는 59, mAP는 74%를 기록했다. 속도는 굉장히 빠른 편이며, (512, 512) 이미지에서는 76.9%를 달성하여 Faster R-CNN보다 더 좋은 결과를 얻기도 했다. 또한 저해상도에서도 높은 성능을 보이는 것이 SSD의 특징이다.
먼저, Single Shot MultiBox Detector라는 이름을 살펴보자.
Single Shot의 의미는 localization과 classification을 단일의 네트워크를 통과함으로써 할 수 있다는 의미다. YOLO의 경우도 하나의 네트워크를 통과시켜 (x, y, w, h, confidence, classes)와 같은 결과를 얻을 수 있었다. 이러한 모델들을 1-stage detector라고 한다.
MultiBox는 Szegedy et al에 의해 개발된 bounding box regression 기술명이다.
Architecture
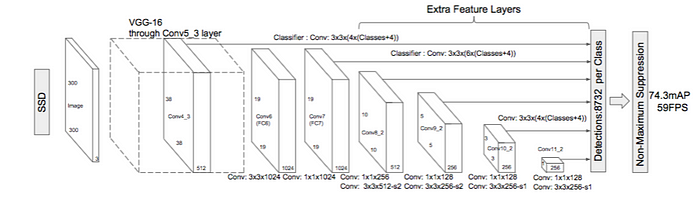
위 그림은 input이 300x300x3 일 때, SSD의 아키텍쳐 구조이다.
SSD는 Transfer learning을 위해 fully-connected layers를 제외한 VGG-16 아키텍쳐를 사용했다. 여기서 transfer learning이란 사전 학습된 모델을 이용해서 새롭게 만드는 모델을 빠르게 학습시키는 것을 말한다. 그 다음 FC layers를 제외한 대신 convolution layers(Extra Feature Layers)를 추가하여 다양한 크기로 feature를 추출하고 각 subsequent layer로 입력의 크기를 점점 감소시켜 나간다.
Extra Feature Layers

Input image가 300x300x3일 때, VGG-16의 conv4_3까지 적용시켰기 때문에 base network의 output은 38x38x512가 된다. 이 feature map에 각각의 convolution layer를 통과시키면
- 38 x 38 x 512
- 19 x 19 x 1024
- 10 x 10 x 512
- 5 x 5 x 256
- 3 x 3 x 256
- 1 x 1 x 256
위와 같은 크기의 feature map이 만들어지고 이것이 논문에서 말하는 multi-scale feature map이다. YOLO는 단일의 feature map에 classifier를 사용하지만, SSD는 여러 feature map에 classifier를 적용한다. 각 feature map에 적절한 conv 연산을 하면 다음과 같은 결과를 얻는다. (stride = 1, padding = 1)
3 x 3 x ( #bounding box x ( classes + offset ) ) / offset : (x, y, w, h)
- 3 x 3 x (4 x (classes + 4))
- 3 x 3 x (6 x (classes + 4))
- 3 x 3 x (6 x (classes + 4))
- 3 x 3 x (6 x (classes + 4))
- 3 x 3 x (4 x (classes + 4))
- 3 x 3 x (4 x (classes + 4))
그래서 총 8732개의 bounding box를 얻게 된다. 이것을 다 고려하는 것은 아니고 마지막에 Non-maximal suppression을 통해 제거한다. Non-maximal suppression은 YOLO 모델의 원리에서 간단히 설명했다.
여기서 주목할 점은 bounding box를 많이 고려한다는 것보다 classifier로 convolution layer를 사용한다는 점이다. 보통 분류 문제에서는 YOLO처럼 CNN 마지막에 FC layers를 붙이는 것이 일반적이었다. 하지만 SSD는 conv layer를 사용해서 연산량과 모델 파라미터 개수도 감소시켜 속도 향상 및 모델 경량화를 이루어냈다. 그래서 YOLOv2에서는 이를 채택해 SSD의 성능을 뛰어넘었다.
Train
훈련 시 사용하는 MultiBox의 loss 함수는 다음과 같다
MultiBox_loss = confidence_loss + alpha * location_loss
objectness를 계산한 신뢰도와 ground truth와 예측 box의 차이 정도의 합이다. 알파는 localization과 objectness에 대한 학습의 균형을 잡아주는 것을 도와주기 위해 설정한다고 생각하면 된다.
더 자세한 요소들이나 학습에 대한 설명은 아래 포스트에 자세히 나와있으니 참고하면 좋다.
'A·I' 카테고리의 다른 글
| [3D face] Morphable Model For The Synthesis Of 3D Faces 리뷰 1편 (0) | 2020.02.14 |
|---|---|
| [object detection] YOLO에서 YOLOv2로의 변경점 (0) | 2019.11.12 |
| [object detection] YOLO 모델의 원리 (9) | 2019.07.22 |
| 주차 구역 인식(Vision-Based Parking-Slot Detection) 논문 리뷰 (12) | 2019.07.04 |
| Keras로 구현하는 DCGAN (4) | 2019.05.26 |



댓글