YOLO 모델의 원리 글에 이어서 YOLO 모델에서 YOLOv2로의 큰 변화 내용을 살펴보겠다.
일단 YOLO에 비해 정확도와 속도 향상이 이루어졌는데 향상하는데 영향을 미친 요소를 살펴보자.
1) Batch normalization 레이어 추가

보통 전체 데이터에 대해 정규화를 하게 되는데 전체적으로 봤을 땐 정규분포 형태를 띄겠지만 각 batch를 살펴보면 위 그림처럼 정규분포가 다를 수 있다. 그렇기 때문에 각 batch마다 정규화를 진행하는 batch normalization 레이어를 추가하여 학습이 잘 되게 하며 학습 속도를 향상시킨다.
2) Convolutional with Anchors

Anchor는 초기 regression 학습을 안정적으로 하게 해주는 역할을 한다. Anchor가 없다면 초기 학습에서는 아무런 정보 없이 object의 크기를 예측해나간다. 그렇게 되면 object의 크기를 정밀하게 맞출 수 있지만 학습이 오래 걸린다. 따라서 사전에 정의된 크기의 boxes를 설정하여 초기 학습을 안정화시킨다.

예를 들어 위 그림과 같이 도로 CCTV 영상에서의 차량 검출이 학습 목적이라면 CCTV 내 차량의 크기에 맞춰 anchors의 크기를 설정하면 된다. Anchor의 도입은 mAP 감소, recall의 증가로 이어진다고 한다.
3) Remove fully-connected layers
예전에 SSD를 포스팅한 적이 있다. SSD는 특별하게 classification을 할 때 fully-connected 레이어가 아닌 CNN 구조를 사용했다. 마찬가지로 YOLOv2에서도 SSD처럼 CNN 구조로 변경시켰다.

위 그림처럼 class 수가 20개라고 할 때 각 boundary box의 출력 parameter는 25개가 된다. 거기에 anchor boxes가 5개라고 하면 1 cell에는 5 x 25 = 125개의 parameter를 출력하게 된다. YOLO와의 변경점은 각 class 확률을 CNN에서 뽑아낸다는 점이다.
4) 네트워크 구조 변경
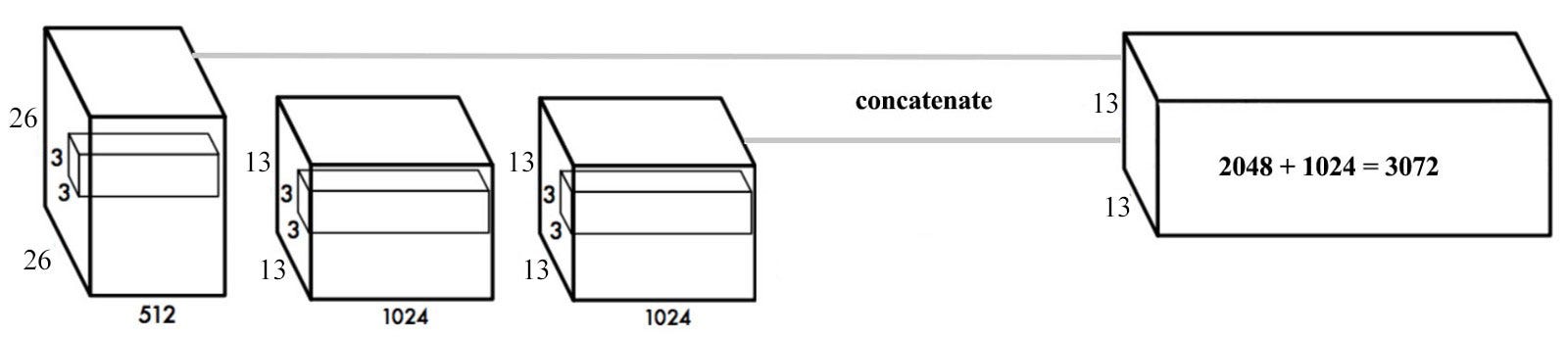
위 변경사항 이외에도 7x7 grid에서 13x13 grid로 변경되었고 작은 object를 잘 탐지하기 위해 passthrough 방식을 도입했다. CNN은 레이어를 지날수록 이미지의 해상도가 낮아져 작은 objects를 탐지하기 어렵기 때문에 위 그림과 같은 passthrough 방식을 통해 여러 레이어의 feature map을 concatenate하여 작은 object도 잘 탐지하게 만든다.
'A·I' 카테고리의 다른 글
| [3D face] Morphable Model For The Synthesis Of 3D Faces 리뷰 2편 (0) | 2020.02.17 |
|---|---|
| [3D face] Morphable Model For The Synthesis Of 3D Faces 리뷰 1편 (0) | 2020.02.14 |
| [object detection] Single Shot Multibox Detector (SSD) 아키텍쳐 분석 (0) | 2019.08.08 |
| [object detection] YOLO 모델의 원리 (9) | 2019.07.22 |
| 주차 구역 인식(Vision-Based Parking-Slot Detection) 논문 리뷰 (12) | 2019.07.04 |


댓글